ASP.NET Repository Pattern Und Unit of Work
In diesem Blog post möchte ich das ASP.NET Repository Pattern and Unit of Work vorstellen. In einem Informationssystem (z.B. Webapplikation) hat man normalerweise immer dasselbe Problem: Irgendwie muss man Daten persistieren und von der Oberfläche im Browser in die Datenbank hin- und wieder zurückschieben. Und dies findet man beinahe bei jedem Objekt (Person, Artikel, Blogeintrage, etc.). Vor allem fällt nach einer Zeit auf, dass die Operationen immer dieselben sind: Create/Read/Update und Delete geben sich die Klinke in die Hand. Dies sind die sogenannten CRUD-Operationen.
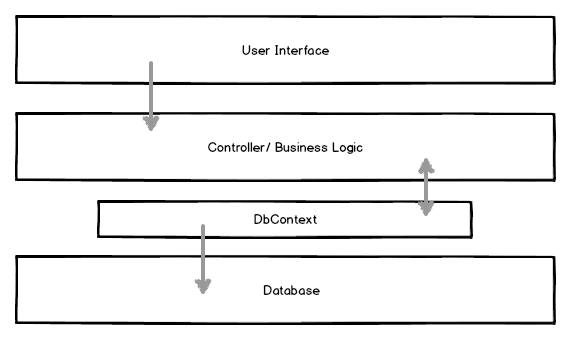
Um diese Datenoperationen so einfach, so sinnvoll und so übersichtlich wie möglich zu halten bietet sich das Repository- in der Kombination mit dem UnitOfWork-Pattern an. Vor allem, aber nicht nur, im Web-Bereich.
Ich werde jetzt kurz beide Ansätze erläutern um danach einen Anwendungsfall mit Code-Beispielen zu zeigen.
Um diese Datenoperationen so einfach, so sinnvoll und so übersichtlich wie möglich zu halten bietet sich das Repository- in der Kombination mit dem UnitOfWork-Pattern an. Vor allem, aber nicht nur, im Web-Bereich.
Ich werde jetzt kurz beide Ansätze erläutern um danach einen Anwendungsfall mit Code-Beispielen zu zeigen.
Repositories:
Das Pattern hilft dem Entwickler beim Aufziehen einer wartbaren, testbaren und übersichtlichen Architektur.
Das Repository-Pattern sieht vor, dass jedes Objekt (sei es ein Kunde, ein Artikel oder ein Blogeintrag) genau eine Schnittstelle hat, an denen es die CRUD-Operationen ausführen kann. Im Prinzip eine Schnittstelle, die auf die Anliegen „Kannst du mir mal alle xyz geben“, „Trage mal einen neuen xyz ein“, „Der xyz hat neue Werte, aktualisiere die mal“ und „Der xyz wird nicht mehr gebraucht“ eine passende Reaktion hat. Diese Schnittstelle oder der Punkt, wo solche Anliegen bearbeitet werden, ist das Repository. Für beinahe jedes Objekt, was persistiert wird.
Gerade bei Webapplikationen gilt: Datenbank-Anfragen sind teuer. Das sind sie wirklich: Denn je nachdem wie viele Anfragen abgesetzt werden kosten diese Zeit. Rechenzeit für den Server, den Anwender kostet dies Zeit, die er am und im Browser merkt und und und. Gerade im Cloud-Bereich wird dies sofort in bares Geld umgewandelt.
Definition des Repository-Patterns von Fowler: > Vermittelt mit Hilfe einer Collection-artigen Schnittstelle für den Zugriff auf Domänenobjekte zwischen den Domänen- und Daten-Mapping-Schichten
Die Vorteile des Patterns sind zum einen die vereinfachten Unit-Tests. Man kann jedes Repositoryeinfach testen und so auf seine korrekte Funktionalität überprüfen. Weiter bieten Repositories eine zentrale Anlaufstelle für Datenbankoperationen. Eine gemeinsame Schnittstelle gegenüber den Datenhaltungs-Schichten. Zudem bietet es einen Punkt, an dem man beispielsweise Mechanismen wie Caching implementieren kann.
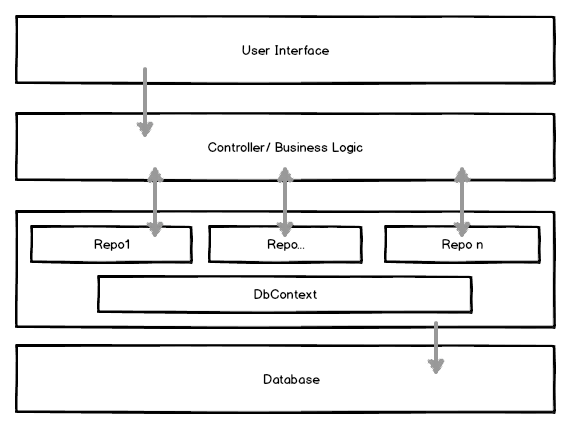
Trotzdem hat man immernoch das „Problem“, dass man jede Abfrage direkt, also unverzüglich, an die Datenbank sendet.
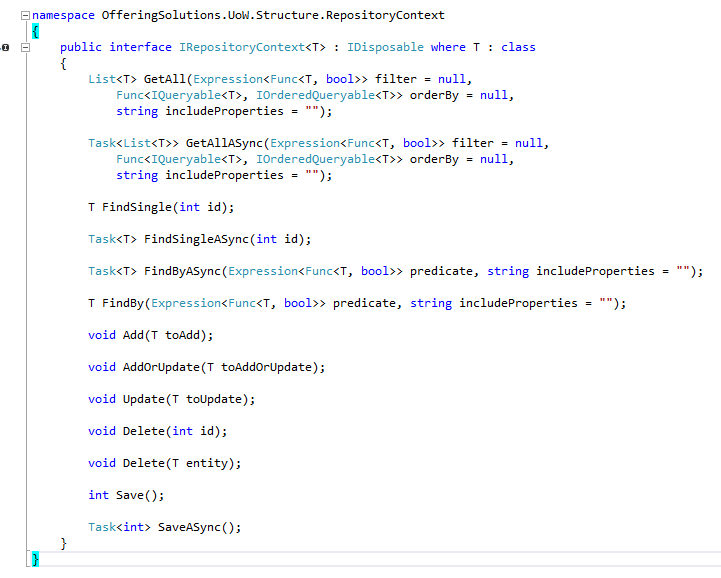
UnitOfWork:
Eine Milderung dieses Umstandes ist das UnitOfWork-Prinzip. Hierbei ist der Name mehr als treffend: Das „UnitOfWork“ ist ein Kontext, der sich alle Datenbankoperationen „notiert“, also alle Veränderungen, die gemacht werden sollen, mitschreibt und sie zum vom Entwickler gewählten Zeitpunkt gegen die Datenbank feuert. Somit werden alle Informationen „auf einmal“ (hierbei laufen wir schon noch synchron, jedoch mit so wenig aufrufen wie möglich) in die Datenbank geschrieben.
UnitOfWork löst also das grundlegende Problem, wie geänderte Objekte im Speicher verwaltet werden können, so dass eine effiziente Synchronisation mit der Datenbank möglich ist.
Schüttet man nun diese beiden Ansätze in einen Topf und gibt ein bisschen generisches dazu, hat man generische Repositories mit dem UnitOfWork-Pattern. Repositories, die grundsätzlich alle Operationen für jeden Dateityp bereitstellen, jedoch erweiterbar sind und alle ihre Änderungen auf einem UnitOfWork speichern, um dann alles gesammelt in eine Datenbank zu schreiben.
Nebenbei: Jeder, der das EntityFramework bisher benutzt hat, hat das UnitOfWork- und das Repository-Pattern schon genutzt. Der „DbContext“ ist schon eine Abstrahierung davon. Wenngleich eine sehr Datenbank-nahe.
Im Folgenden möchte ich so eine Implementierung vorstellen und ein Nuget-Paket von mir vorstellen, das die Arbeit mit dem UnitOfWork so einfach wie möglich macht.
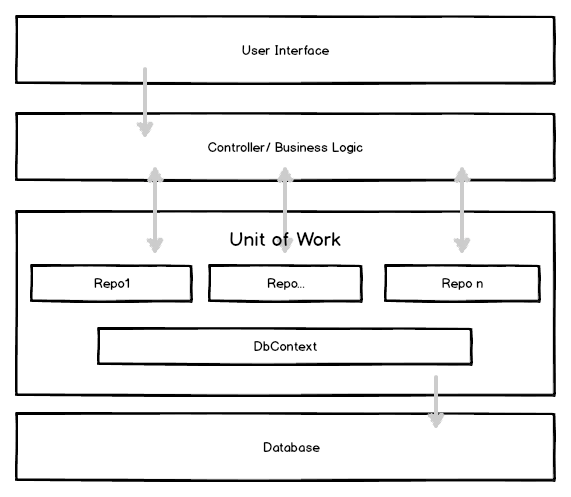
Benutzung des UnitOfWorks:
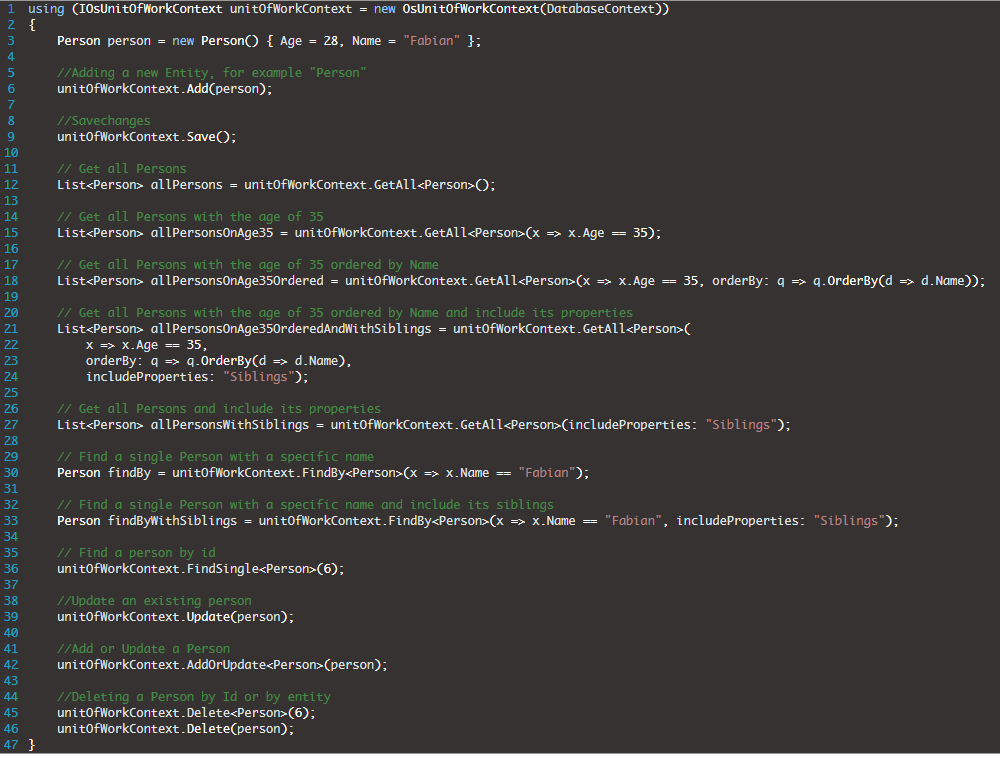
Hierbei werden die Repositories im Prinzip generisch und implizit vom UnitOfWork zur Verfügung gestellt. Aber um das Testing zu verbessern und eine bessere Aufteilung zu gewährleisten kann und sollte man eigene Klassen für die Repositories erstellen und nutzen.
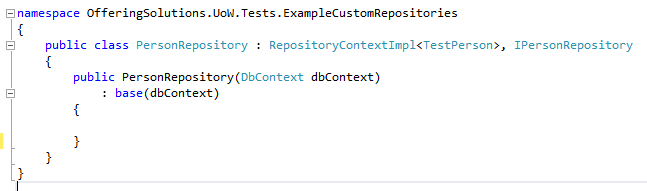
Eine mögliche Aufteilung im Projekt könnte wie folgt aussehen (Am Beispiel eines Blog-Repositories)
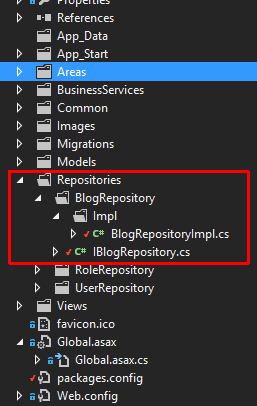
Verwendung könnte beispielsweise sein:
public class AdminAreaServiceImpl : IAdminAreaService
{
private readonly IBlogRepository _blogRepository;
private readonly IUserRepository _userRepository;
public AdminAreaServiceImpl(IUserRepository userRepository, IBlogRepository blogRepository)
{
_blogRepository = blogRepository.CheckIsNull("blogRepository");
_userRepository = userRepository.CheckIsNull("userRepository");
}
public AdminIndexViewModel AddBlog(AddBlogSubmitModel addBlogSubmitModel, string userName)
{
AdminIndexViewModel viewModel = GetAdminIndexViewModelInternal(null, addBlogSubmitModel);
if (!_modelValidator.IsSubmitModelValid(viewModel, addBlogSubmitModel))
{
return viewModel;
}
Blog blog = new Blog();
blog.Headline = addBlogSubmitModel.Headline;
blog.Text = addBlogSubmitModel.Text;
blog.Added = DateTime.Now;
blog.WrittenBy = _userRepository.GetUser(userName);
_blogRepository.Add(blog);
_blogRepository.Save();
viewModel.InfoMessages.Add("Blog Added");
return viewModel;
}
}
Der Code aus dem Beispiel und die oben erwähnte Verwendung benutzt das UnitOfWork-Paket welches bei Nuget verwendbar ist.
NuGet – UnitOfWork





